
Wer eigene Sprachmodelle lokal betreibt, will sie natürlich auch direkt im Code-Editor nutzen – ohne Cloud-Abo, ohne dass der eigene Code auf fremde Server wandert.
LM Studio macht genau das möglich: Es läuft im Hintergrund als lokaler API-Server und lässt sich über eine Erweiterung direkt in VS Code einbinden. Ich zeige Ihnen, wie das in der Praxis funktioniert.
Was Sie dafür brauchen
Bevor Sie loslegen, sollten zwei Programme installiert sein: (https://lmstudio.ai) und (https://code.visualstudio.com). LM Studio ist kostenlos und läuft auf Windows, macOS und Linux. Für die Verbindung brauchen Sie außerdem die VS-Code-Erweiterung „Continue“, die als Brücke zwischen dem lokalen Modell und dem Editor fungiert.
Ein Wort zu den Systemanforderungen: LM Studio läuft grundsätzlich auch ohne dedizierte GPU, aber mit einer modernen Nvidia-Grafikkarte mit mindestens 8 GB VRAM werden die Antwortzeiten deutlich angenehmer. Auf reiner CPU-Basis ist es zwar möglich, aber bei größeren Modellen wird das Warten schnell zur Geduldsprobe.
Schritt 1: Modell in LM Studio laden und Server starten
Öffnen Sie LM Studio und wechseln Sie über das Lupensymbol in der linken Leiste zur Modellsuche. Für Coding-Aufgaben empfehle ich Ihnen Qwen2.5 Coder oder DeepSeek Coder – beide sind speziell auf Programmieraufgaben trainiert und bringen auch auf mittlerer Hardware brauchbare Ergebnisse. Für schwächere Rechner ist die 7B-Variante ein guter Startpunkt, ab 16 GB RAM können Sie auch 14B-Modelle ausprobieren.
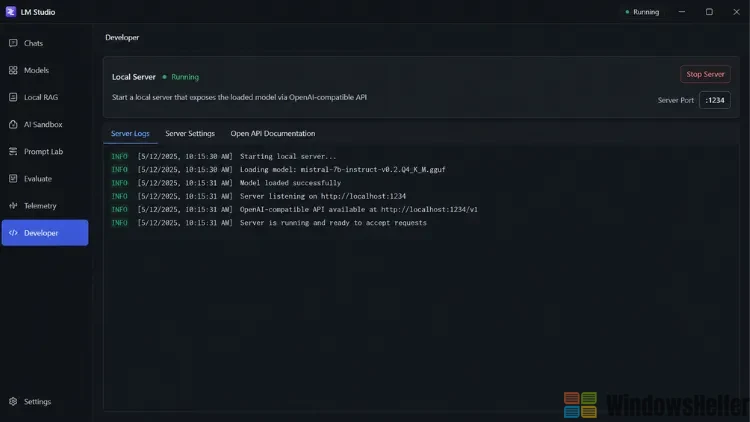
Sobald das Modell heruntergeladen ist, laden Sie es über die Chat-Ansicht, um kurz zu prüfen, ob es grundsätzlich funktioniert. Wechseln Sie danach in der linken Seitenleiste zum Reiter Developer (erkennbar am Pfeilsymbol). Dort sehen Sie oben den Button Start Server – klicken Sie darauf.
Der Server startet dann auf http://localhost:1234 und zeigt Ihnen die verfügbaren API-Endpunkte an. Den genauen Port sehen Sie oben rechts im Developer-Fenster – in seltenen Fällen kann LM Studio auch einen anderen Port vergeben, zum Beispiel 2345. Merken Sie sich diesen Wert, denn er wird später noch gebraucht.
Wichtig: LM Studio muss während der gesamten Nutzung in VS Code geöffnet und der Server aktiv bleiben. Das Programm darf also nicht geschlossen oder in den Ruhezustand versetzt werden.
Schritt 2: Continue-Erweiterung in VS Code installieren
Starten Sie VS Code, öffnen Sie die Erweiterungsleiste und suchen Sie nach „Continue“. Installieren Sie die Erweiterung aus dem VS Code Marketplace und öffnen Sie sie anschließend über die Seitenleiste.
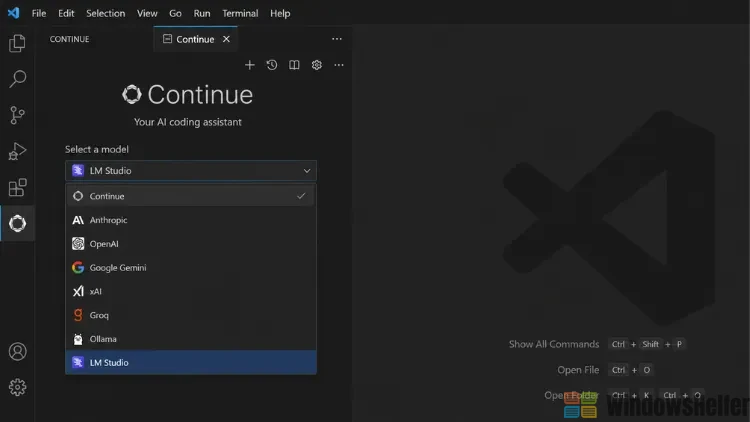
Nach der Installation erscheint in der linken Aktivitätsleiste ein neues Symbol – das ist das Continue-Panel. Wenn Sie es öffnen, sehen Sie ein Chat-Eingabefeld. Noch reagiert es nicht, weil kein Modell konfiguriert ist.
Klicken Sie im Models-Bereich auf Add chat model, dann auf das Provider-Dropdown und wählen Sie LM Studio. Lassen Sie die Modell-Option auf Autodetect stehen – Continue erkennt das laufende Modell automatisch – und bestätigen Sie mit Connect.
In vielen Fällen reicht das bereits, und Sie können direkt im Chat-Feld die erste Frage eingeben. Wenn Autodetect nicht greift, müssen Sie das Modell manuell in der Konfigurationsdatei eintragen – dazu gleich mehr.
Die Konfigurationsdatei manuell bearbeiten
Continue speichert seine Einstellungen in einer YAML-Datei, die Sie bei Bedarf direkt bearbeiten können. Die Standard-Konfiguration für LM Studio sieht so aus:
name: My Config
version: 0.0.1
schema: v1
models:
- name: LM Studio Modell
provider: lmstudio
model: AUTODETECT
apiBase: http://localhost:1234/v1
Der Standardwert für apiBase ist http://localhost:1234/v1.
Wenn LM Studio bei Ihnen auf einem anderen Port läuft, passen Sie die apiBase-Zeile entsprechend an, also zum Beispiel http://localhost:2345/v1. Die Konfigurationsdatei öffnen Sie direkt über das Zahnrad-Symbol im Continue-Panel.
Für getrennte Rollen – ein größeres Modell für Chat und Erklärungen, ein kleineres für schnelle Code-Vervollständigung – können Sie mehrere Modelle mit unterschiedlichen Rollen eintragen:
models:
- name: Qwen Coder Chat
provider: lmstudio
model: qwen2.5-coder-14b
apiBase: http://localhost:1234/v1
roles:
- chat
- edit
- name: Qwen Autocomplete
provider: lmstudio
model: qwen2.5-coder-1.5b-instruct
apiBase: http://localhost:1234/v1
roles:
- autocomplete
Diese Aufteilung macht Sinn, weil das größere Modell für die schwereren Denkaufgaben zuständig ist, während das kleinere Modell schnelle Inline-Vorschläge liefert. Das kleinere Modell muss dafür allerdings separat in LM Studio geladen sein.
Code-Autovervollständigung einrichten
Die Tab-Vervollständigung ist aus meiner Sicht das nützlichste Feature dieser Kombination. Sie schreiben an einer Funktion, drücken Tab, und Continue schlägt die Fortsetzung vor – grau hinterlegt, wie man es von GitHub Copilot kennt.
Damit das funktioniert, muss in der Konfigurationsdatei ein Modell mit der Rolle autocomplete eingetragen sein, wie oben gezeigt. Wählen Sie dafür ein kleineres Modell – die Q4-Quantisierung reicht in der Regel aus und spart Arbeitsspeicher.
Ob die Vervollständigung aktiv ist, erkennen Sie an einem kleinen Indikator in der VS-Code-Statusleiste. Über die Continue-Einstellungen können Sie die Funktion auch vorübergehend deaktivieren, falls sie beim Schreiben von Kommentaren oder Texten stört.
Fehlersuche: Wenn die Verbindung nicht klappt
Manchmal meldet Continue einen Fehler, obwohl LM Studio läuft. In diesem Fall hilft eine kurze Checkliste:
Prüfen Sie zuerst, ob der LM Studio-Server tatsächlich auf Port 1234 läuft – das sehen Sie im Developer-Tab. Vergewissern Sie sich außerdem, dass im Developer-Bereich ein Modell aktiv geladen ist. Wenn Continue eine API-Schlüssel-Eingabe verlangt, tragen Sie einfach einen Platzhalter wie „none“ oder „dummy“ ein. Starten Sie danach sowohl LM Studio als auch VS Code neu.
Ein weiterer häufiger Grund für ausbleibende Antworten ist, dass das Modell schlicht nicht in den Arbeitsspeicher gepasst hat. Wenn Sie im LM Studio-Ausgabefenster Fehler sehen, deutet das oft darauf hin, dass das Modell zu groß für den verfügbaren RAM ist – wechseln Sie dann zu einer kleineren Quantisierungsstufe wie Q4.
Die wichtigsten Tastenkürzel in Continue
Sobald alles läuft, lohnt es sich, die Shortcuts zu kennen, die den Workflow beschleunigen. Mit Strg+L fügen Sie markierten Code zum Chat-Kontext hinzu, mit Strg+I öffnen Sie direkt ein Eingabefeld für Code-Generierung oder -Bearbeitung an der aktuellen Cursor-Position. Der generierte Code lässt sich dann mit einem Klick übernehmen oder verwerfen – das erinnert stark an die Inline-Bearbeitung aus Copilot, funktioniert aber komplett lokal.
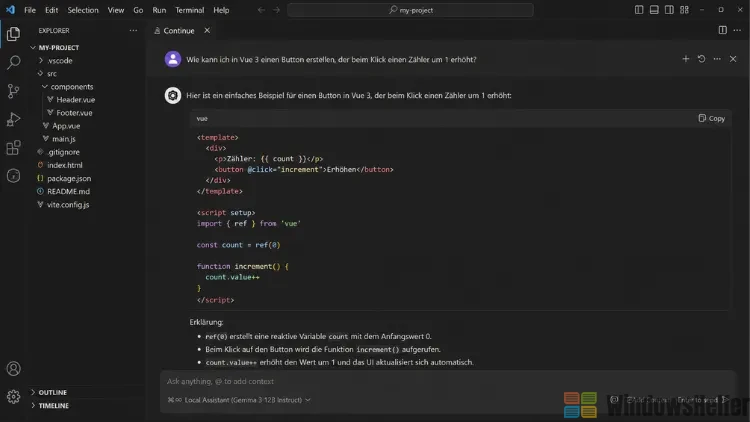
Einen API-Schlüssel brauchen Sie für all das nicht, und Ihr Code verlässt zu keinem Zeitpunkt Ihren Rechner. Das ist aus Datenschutzsicht besonders für Projekte mit vertraulichem Code ein echter Vorteil – ich nutze die lokale Variante deshalb selbst dann, wenn ich Internetzugang hätte.
